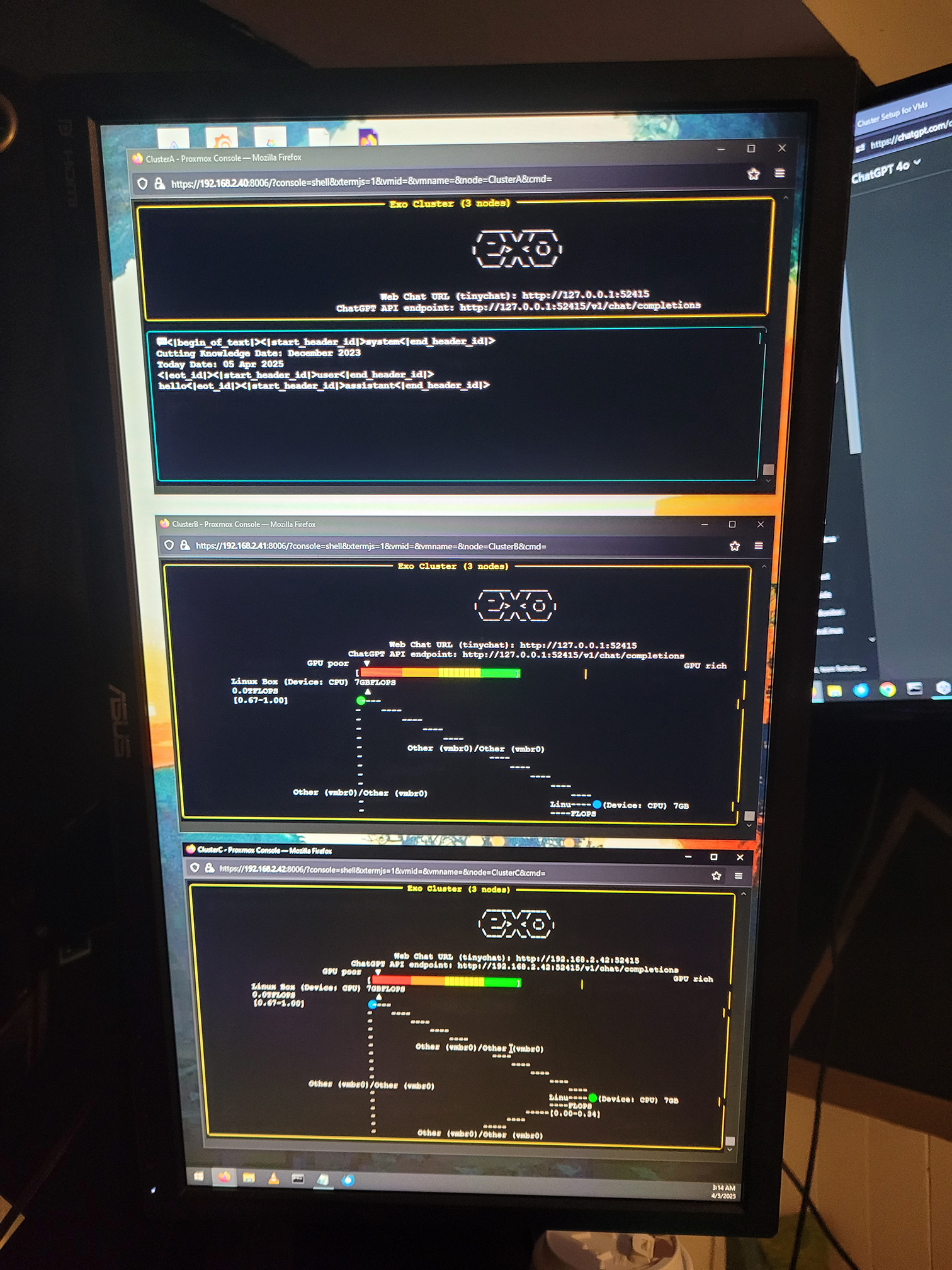
I recently explored setting up Exo, a framework for distributing large language models (LLMs) across multiple nodes in a cluster. The goal was to create a powerful offline AI assistant by utilizing my 3-node Proxmox VE cluster.
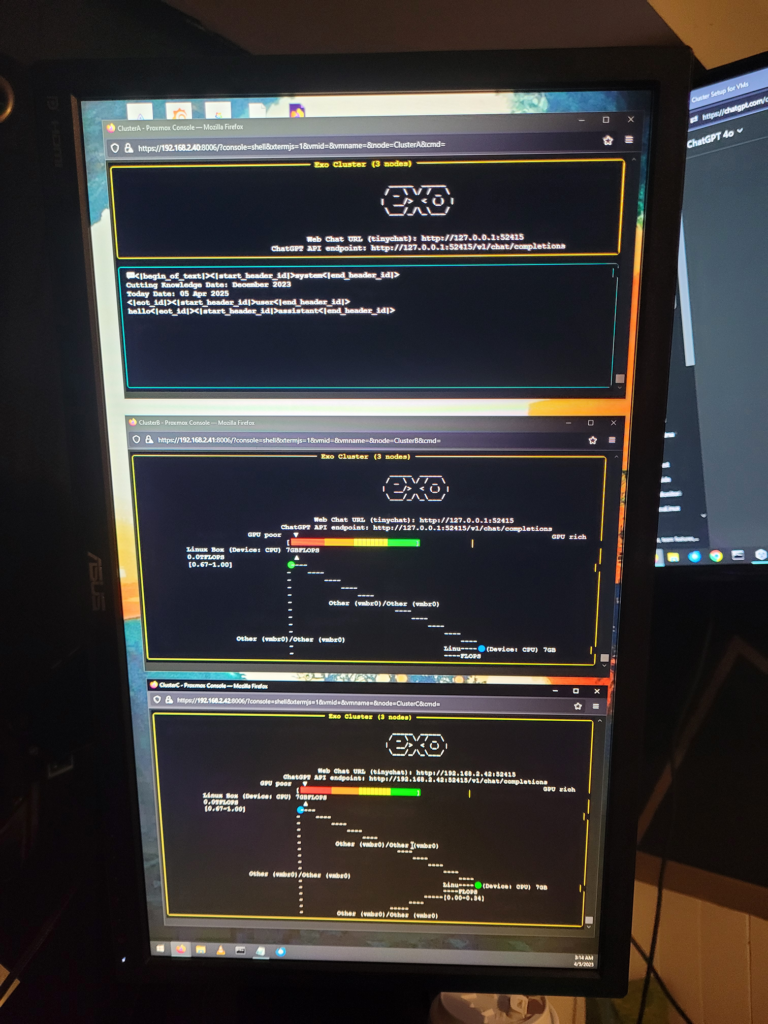
My nodes are uniform, each with:
- Intel HD Graphics 530 (integrated GPU)
- Multi-core CPUs (no AVX-512)
- 16 GB RAM per node
- Running lightweight VMs with Debian-based distros
This blog post outlines my experience, step-by-step setup, issues I encountered, and ultimately why I could not use Exo effectively in this configuration.
Why Exo?
Exo promises:
- Distributed inference for LLMs (like Mistral or LLaMA)
- Support for containerized node deployment
- Scalability with multiple compute nodes
- Open-source and locally hosted
It’s a promising project, especially for offline use in homelab environments.
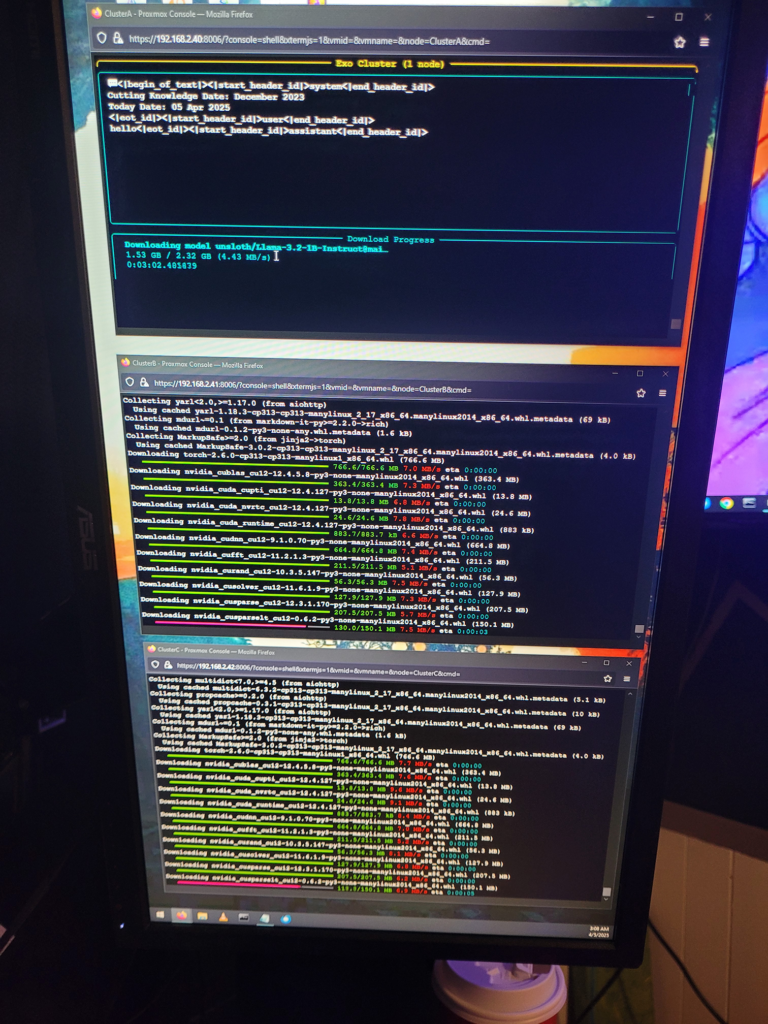
Step-by-Step Installation Summary
1. Git Clone and Setup
git clone https://github.com/exo-explore/exo.git
cd exo2. Install Prerequisites (on all nodes)
sudo apt update && sudo apt install -y python3 python3-venv build-essential git3. Create Python venv
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txtAfter installing countless dependencies, I finally got this running on all 3 nodes, and all three nodes could see each other. Everything looked to be running smoothly at this point. When I tried to interact with AI, the program would just error out. Basically due to my lack of GPU hardware on the cluster.
Issues Encountered
🚫 No GPU Support for Exo Inference
- Exo requires GPU acceleration to function efficiently.
- My hardware (Intel HD 530) has no CUDA, no ROCm, and no OpenCL support for PyTorch.
- CPU-only fallback is not officially supported or extremely inefficient.
🛠 Incompatibility with Llama.cpp
Some models I tested (GGUF via llama.cpp) were not compatible with Exo’s loading mechanism.
⚠️ Lack of Community Support for CPU-only Clusters
Very few users seem to be running Exo without GPUs. Issues related to CPU fallback were largely unanswered or marked as unsupported.
Workarounds I Attempted
- ✅ Tried smaller models (TinyLLaMA, Phi-2 quantized) — still slow or failed to start
- ✅ Lowered worker thread count and concurrency — still slow or failed to start
- ✅ Rewrote config for minimal parallelism — still slow or failed to start
Final Decision: Move to Ollama + Load Balancing
Due to lack of GPU support, I chose to:
- Decommission Exo from my stack
- Use Ollama instead — it runs well on CPU-only systems
- Deploy one model per node in my Proxmox cluster
- Build a load balancer + lightweight chat UI to mimic distributed inference
My Conclusions
While Exo is a very exciting project and I so wish I had it running on this cluster, it’s currently not viable for:
- Clusters without dedicated NVIDIA or AMD GPUs
- Homelabs with integrated graphics only
If you’re in a similar situation and want to run LLMs locally:
- ✅ Use Ollama for GGUF models (CPU-optimized)
- ✅ Explore Text Generation WebUI or LM Studio
- ✅ Create a local load-balanced endpoint for pseudo-clustered inference
I will be adding a new server to my home lab with an Nvidia GPU, so I will have this running eventually.
Hopefully Exo evolves to support CPU clusters in the future — I’ll be watching!
