Today, I decided to play around and check exactly how much juice my home AI rig pulls when running a local Ollama LLM (Llama3.1:8B). No deep-dive benchmarks, just a quick, fun peek at the total wall-meter draw. Here’s what went down:
The Setup
- Server CPU: Intel i7
- RAM: 32 GB
- GPUs (via Proxmox GPU Passthrough):
- NVIDIA GTX 1060
- NVIDIA RTX 2070
- Environment: This node is part of a Proxmox cluster, dedicated to AI tasks via GPU passthrough for virtual machines.
What Happened
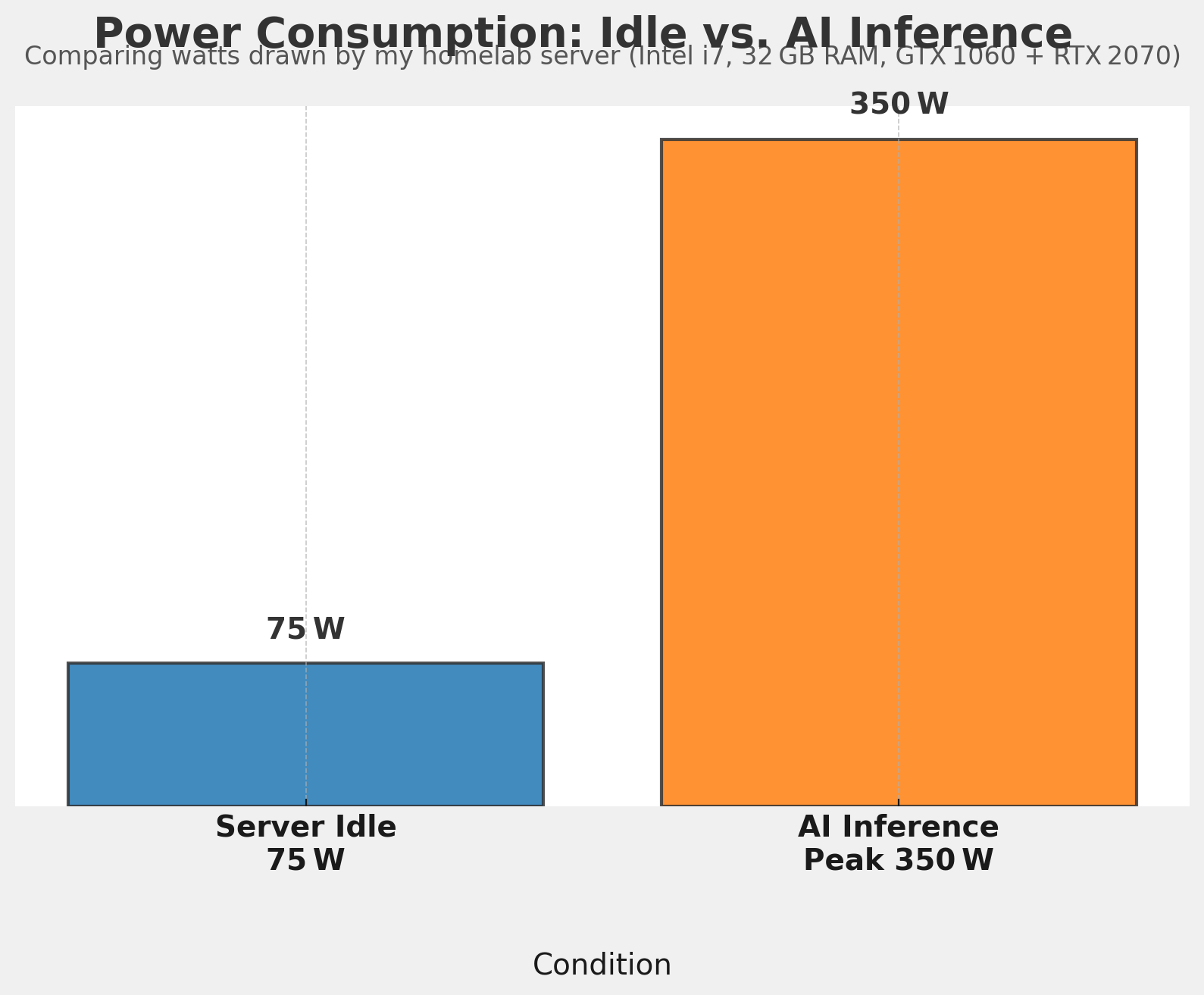
I simply ran the Ollama LLM on this server and watched the power meter. No fuss—just plugged it in, let it run, and noted the numbers. The idle draw hovered around 75 W, but as soon as the AI kicked into high gear, my outlet meter spiked to about 350 W! 😲 That’s right, no splitting hairs over each component: just the total, real-world picture.
Why This Matters
Running LLMs locally is awesome for privacy and flexibility, but it’s good to know the cost (literally) in watts. Whether you’re experimenting in a homelab or curious about running AI on mid-tier hardware, seeing the jump from an idle 75 W to about 350 W can be eye-opening.
Let’s Visualize It
Here’s a quick graphic comparing the server’s idle draw versus that AI inference peak:
Key Takeaway
- Idle: ~75 W
- AI Inference Peak: ~350 W
Hardware efficiency can vary. Your numbers might be lower with more efficient components or even higher if your rig’s a beast. But hey, isn’t it wild how much power an 8B‑parameter model can swallow in a flash?
Have you ever measured your homelab or gaming rig’s power draw while running an AI model? What numbers did you see, and did it make you do a double-take like I did? Drop your story (or your own surprise watts) in the comments!
